Subglacial bedrock frost heave: basic model

Relict subglacial bedrock frost heave - Isthmus of Avalon
The Subglacial Ice Plume model provides an explanation for the widespread disruption of bedrock by ice on Newfoundland's Avalon Peninsula during the latter portion of the Younger Dryas cold period. Using the Subglacial Ice Plume model as a basis, a description (Basic Model) of the frost heave process that controls the development of frost-heaved monoliths and related features in a subglacial environment can be laid out. This Basic Model is the subglacial equivalent of the commonly recognized subaerial model for bedrock frost heave occurring in a periglacial environment. The Basic Model is configured to reflect the special conditions that characterized the glacial geology on the Avalon Peninsula leading up to the end of the Pleistocene. These special conditions start with phyllosilicate-rich ancient bedrock that was intensely foliated by regional metamorphism. Superimposed on this low-grade metamorphic bedrock geology is a late Pleisticene glacial history that evolves from thick warm-based glacial ice cover, transitioning to cold-based glacial ice cover and then to deglaciation under cold, dry (polar desert) conditions.
Basic Model
Groundwater migration and ice segregation:
The Basic Model for subglacial bedrock frost heave entails groundwater (as pore water) migrating through frozen foliated bedrock and reaching an interface between bedrock and cold glacial ice. At or near the ice/bedrock interface, an ice segregation process commences. Newly formed ice augments glacial ice already present, resulting in non-tangential glacial ice flow. Ice flow diverges from the bedrock at the ice-bedrock interface.
How does super-cooled groundwater move through frozen foliated bedrock? This remains a key unanswered question. Difficulty in addressing the question arises from the low rate of pore water migration needed to drive subglacial bedrock frost-heave processes that may unfold over centuries. Field observations at specific locations on the Avalon suggest that frozen foliated bedrock is intrinsically permeable to water molecules migrating at a nonzero rate and that groundwater can move through foliated bedrock without macroscopically disrupting the rock. However, when frozen bedrock is not sufficiently confined, disruptive ice segregation will commence. Hydraulic action is the probable catalyst to initiate the widening of gaps between bedrock crystals until nucleation and growth of ice crystals becomes thermodynamically favored. The crystal growth pressure of ice accumulating between bedrock planes augments the width of the gap between the planes. The overall process can be termed joint widening although it is uncertain as to whether the conventional definition of a "joint" is sufficiently broad to encompass weaknesses between phyllosilicate layers in foliated bedrock. The number of possible water-conducting "joints" in foliated phyllosilicate-rich bedrock is seemingly near-infinite.
The process of ice segregation intrinsically embodies a positive feedback loop. Once a domain of crystallized water (ice) forms, its growth is thermodynamically favored at the expense of the concentration of nearby free-roaming water molecules. There are three key requisites that will tend to limit the self-perpetuating growth of a region of segregated ice.
1) Availability of uncrystallized feed-water.
2) Space for the ice domain to increase in size without increasing ambient pressure to a level where crystallization is no longer thermodynamically favored.
3) A temperature gradient sufficient to remove heat of crystallization and prevent temperature from rising to a point where crystallization is no longer thermodynamically favored.
Given that the three conditions are met, the positive feedback intrinsic to an ice segregation process will lead to eventual chaotic macroscopic disruption of any bedrock tending to confine the process (bedrock frost heave).
Subglacial conditions:
Ice segregation can occur in bedrock beneath an arbitrary thickness of cold-based glacial ice. There must, however be a feed of uncrystallized water (pore water) that migrates toward the frozen bedrock/glacier interface (subglacial artesian aquifer). Super-cooled pore water is prevented from crystallizing by the interaction with adjacent bedrock molecules in tight confining channels (Gibbs-Thomson). An artesian aquifer can arise during unloading of bedrock as deglaciation proceeds (Subglacial Ice Plume model).
The overlying glacier must be cold (ice thermodynamically favored over water at ambient pressure) and zones of ice segregation must remain cold as ice crystallization progressively adds heat. Heat removal from the immediate site of ice segregation is via conduction.
Advective heat transfer can augment or dominate bulk heat removal by thermal conduction, a process particularly relevant in cases where overlying ice is thick (temperature gradient is low) or the heat source is localized. The occurrence of ice segregation in a localized region (Subglacial Ice Plume) is promoted by the efficient advective heat removal that occurs when cold glacial ice moves tangentially across a zone of heat-evolution (ice segregation).
The density reduction of water upon freezing does not play a significant role in subglacial bedrock frost heave. The frost heave process is solely the result of hydraulic pressure and ice crystal growth pressure combining to slowly disrupt bedrock in a cold non-equilibrium subglacial environment.
The Basic Model for subglacial bedrock frost heave entails groundwater (as pore water) migrating through frozen foliated bedrock and reaching an interface between bedrock and cold glacial ice. At or near the ice/bedrock interface, an ice segregation process commences. Newly formed ice augments glacial ice already present, resulting in non-tangential glacial ice flow. Ice flow diverges from the bedrock at the ice-bedrock interface.
How does super-cooled groundwater move through frozen foliated bedrock? This remains a key unanswered question. Difficulty in addressing the question arises from the low rate of pore water migration needed to drive subglacial bedrock frost-heave processes that may unfold over centuries. Field observations at specific locations on the Avalon suggest that frozen foliated bedrock is intrinsically permeable to water molecules migrating at a nonzero rate and that groundwater can move through foliated bedrock without macroscopically disrupting the rock. However, when frozen bedrock is not sufficiently confined, disruptive ice segregation will commence. Hydraulic action is the probable catalyst to initiate the widening of gaps between bedrock crystals until nucleation and growth of ice crystals becomes thermodynamically favored. The crystal growth pressure of ice accumulating between bedrock planes augments the width of the gap between the planes. The overall process can be termed joint widening although it is uncertain as to whether the conventional definition of a "joint" is sufficiently broad to encompass weaknesses between phyllosilicate layers in foliated bedrock. The number of possible water-conducting "joints" in foliated phyllosilicate-rich bedrock is seemingly near-infinite.
The process of ice segregation intrinsically embodies a positive feedback loop. Once a domain of crystallized water (ice) forms, its growth is thermodynamically favored at the expense of the concentration of nearby free-roaming water molecules. There are three key requisites that will tend to limit the self-perpetuating growth of a region of segregated ice.
1) Availability of uncrystallized feed-water.
2) Space for the ice domain to increase in size without increasing ambient pressure to a level where crystallization is no longer thermodynamically favored.
3) A temperature gradient sufficient to remove heat of crystallization and prevent temperature from rising to a point where crystallization is no longer thermodynamically favored.
Given that the three conditions are met, the positive feedback intrinsic to an ice segregation process will lead to eventual chaotic macroscopic disruption of any bedrock tending to confine the process (bedrock frost heave).
Subglacial conditions:
Ice segregation can occur in bedrock beneath an arbitrary thickness of cold-based glacial ice. There must, however be a feed of uncrystallized water (pore water) that migrates toward the frozen bedrock/glacier interface (subglacial artesian aquifer). Super-cooled pore water is prevented from crystallizing by the interaction with adjacent bedrock molecules in tight confining channels (Gibbs-Thomson). An artesian aquifer can arise during unloading of bedrock as deglaciation proceeds (Subglacial Ice Plume model).
The overlying glacier must be cold (ice thermodynamically favored over water at ambient pressure) and zones of ice segregation must remain cold as ice crystallization progressively adds heat. Heat removal from the immediate site of ice segregation is via conduction.
Advective heat transfer can augment or dominate bulk heat removal by thermal conduction, a process particularly relevant in cases where overlying ice is thick (temperature gradient is low) or the heat source is localized. The occurrence of ice segregation in a localized region (Subglacial Ice Plume) is promoted by the efficient advective heat removal that occurs when cold glacial ice moves tangentially across a zone of heat-evolution (ice segregation).
The density reduction of water upon freezing does not play a significant role in subglacial bedrock frost heave. The frost heave process is solely the result of hydraulic pressure and ice crystal growth pressure combining to slowly disrupt bedrock in a cold non-equilibrium subglacial environment.
Joint Widening
The process of joint widening by ice segregation in a subglacial environment is discussed in more detail, with observations, in the section Joint Widening (pending). The topic is considered here because joint widening is integrally associated with aspects of subglacial bedrock frost heave, including the formation of frost-heaved monoliths.
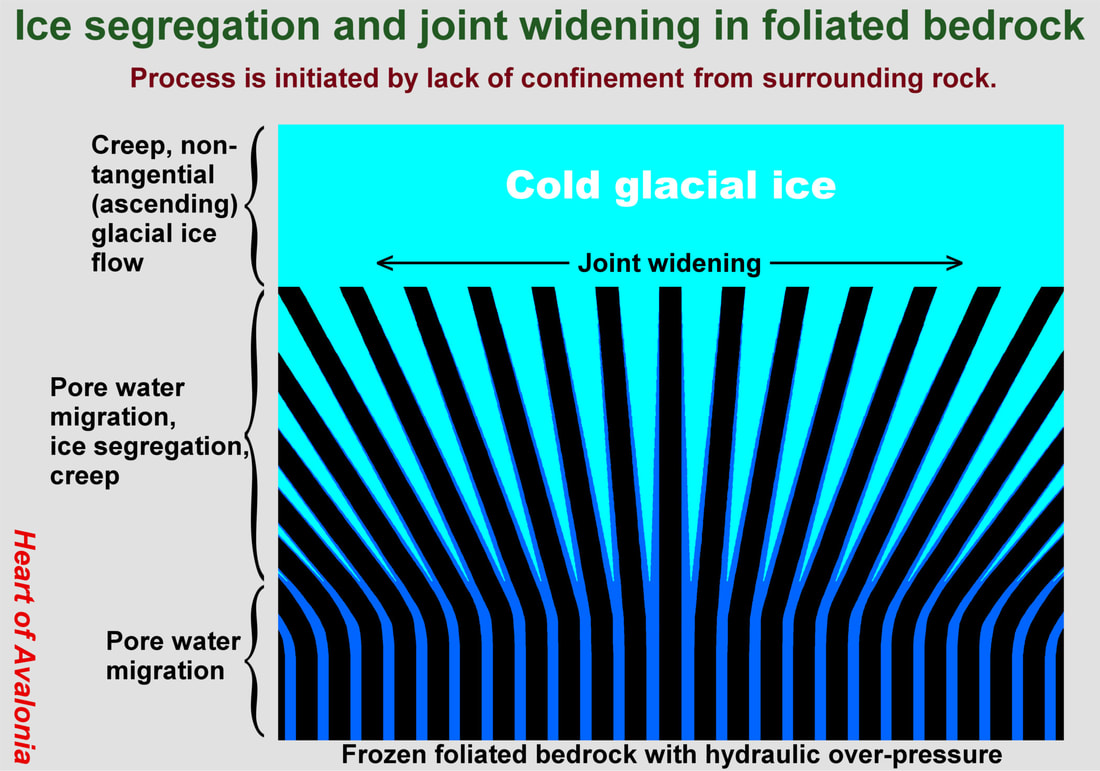
The above diagram shows three zones of interest associated with the interface between bedrock and cold glacial ice. The bottom zone comprises a region of undisrupted foliated bedrock that could be tens or hundreds of meters thick. This bottom zone is permeated with unfrozen groundwater at an ambient pressure exceeding the hydrostatic pressure at the base of the overlying glacier. The foliated bedrock is water-permeable, but excessive bulk flow of groundwater is prevented by a lack of sufficiently wide channels. The temperature of the bedrock in the bottom zone can be above or below the melting point of ice at ambient pressure.
The middle zone is a zone of ice segregation that results from subfreezing rock temperatures and insufficient confinement of bedrock by adjacent bedrock or adjacent ice. The pressurized aquifer places insufficiently-confined bedrock in tension. Since the crystal bonding between adjacent planes of foliated phyllosilicate rock is weak, the rock will yield when placed in tension. When planes of rock separate, the layer of water molecules between the planes thickens and the thermodynamic barrier to water crystallization diminishes. After ice crystals nucleate, they steadily grow by accretion, generating additional pressure against the side walls of confining channels. This process (ice segregation) increases tensile pressure in bedrock and augments joint widening.
The vertical thickness (vertical defined as per above diagram) of the ice-segregation zone is determined by the degree of bedrock confinement, hence by subglacial bedrock topography. In cases where confinement is strong (bottoms of valleys, extended flat planes), ice segregation occurs directly against the base of an overlying glacier (thickness of ice-segregation zone is zero). Little joint widening or bedrock frost heave would be expected in this instance. In cases where confinement is weak (tops of hills, narrow ridges, convex surfaces and slopes) the ice-segregation zone can be thick. Extensive joint widening and bedrock frost heave would then be expected. The thickness of the ice-segregation zone as determined by subglacial bedrock confinement geometry could be considered in some ways analogous to the thickness of the active layer in a permafrost environment supporting subaerial bedrock frost heave.
Anecdotally, observations of ice-induced bedrock disruption on the Avalon Peninsula show a distinct positive correlation between convex bedrock landforms and the frequency and severity of frost-heave occurrences. This observation may be colored by the tendency of glacial till or other debris to accumulate in concave regions and potentially conceal bedrock frost heave features.
Ice accumulating in the ice-segregation zone must leave the zone via creep deformation. The shear stress associated with ice creep close to an ice-rock boundary loads the adjacent rock. It is thus reasonable to assume that fragments of rock will be separated from bedrock and entrained in the ice advancing into the overlying glacier. Large fragments (joint blocks) would comprise instances of bedrock frost heave. Tiny fragments would constitute erosion of the walls of narrow fissures and would contribute to an overall joint-widening process.
When ice diverging from bedrock clears the immediate vicinity of the rock (top zone in diagram), the ice is free to move without undergoing additional deformation. Once ice-deformation rates become insignificant, ice motion diverging from rock surfaces would be described as flow, rather than creep.
The middle zone is a zone of ice segregation that results from subfreezing rock temperatures and insufficient confinement of bedrock by adjacent bedrock or adjacent ice. The pressurized aquifer places insufficiently-confined bedrock in tension. Since the crystal bonding between adjacent planes of foliated phyllosilicate rock is weak, the rock will yield when placed in tension. When planes of rock separate, the layer of water molecules between the planes thickens and the thermodynamic barrier to water crystallization diminishes. After ice crystals nucleate, they steadily grow by accretion, generating additional pressure against the side walls of confining channels. This process (ice segregation) increases tensile pressure in bedrock and augments joint widening.
The vertical thickness (vertical defined as per above diagram) of the ice-segregation zone is determined by the degree of bedrock confinement, hence by subglacial bedrock topography. In cases where confinement is strong (bottoms of valleys, extended flat planes), ice segregation occurs directly against the base of an overlying glacier (thickness of ice-segregation zone is zero). Little joint widening or bedrock frost heave would be expected in this instance. In cases where confinement is weak (tops of hills, narrow ridges, convex surfaces and slopes) the ice-segregation zone can be thick. Extensive joint widening and bedrock frost heave would then be expected. The thickness of the ice-segregation zone as determined by subglacial bedrock confinement geometry could be considered in some ways analogous to the thickness of the active layer in a permafrost environment supporting subaerial bedrock frost heave.
Anecdotally, observations of ice-induced bedrock disruption on the Avalon Peninsula show a distinct positive correlation between convex bedrock landforms and the frequency and severity of frost-heave occurrences. This observation may be colored by the tendency of glacial till or other debris to accumulate in concave regions and potentially conceal bedrock frost heave features.
Ice accumulating in the ice-segregation zone must leave the zone via creep deformation. The shear stress associated with ice creep close to an ice-rock boundary loads the adjacent rock. It is thus reasonable to assume that fragments of rock will be separated from bedrock and entrained in the ice advancing into the overlying glacier. Large fragments (joint blocks) would comprise instances of bedrock frost heave. Tiny fragments would constitute erosion of the walls of narrow fissures and would contribute to an overall joint-widening process.
When ice diverging from bedrock clears the immediate vicinity of the rock (top zone in diagram), the ice is free to move without undergoing additional deformation. Once ice-deformation rates become insignificant, ice motion diverging from rock surfaces would be described as flow, rather than creep.
Frost-heaved monoliths
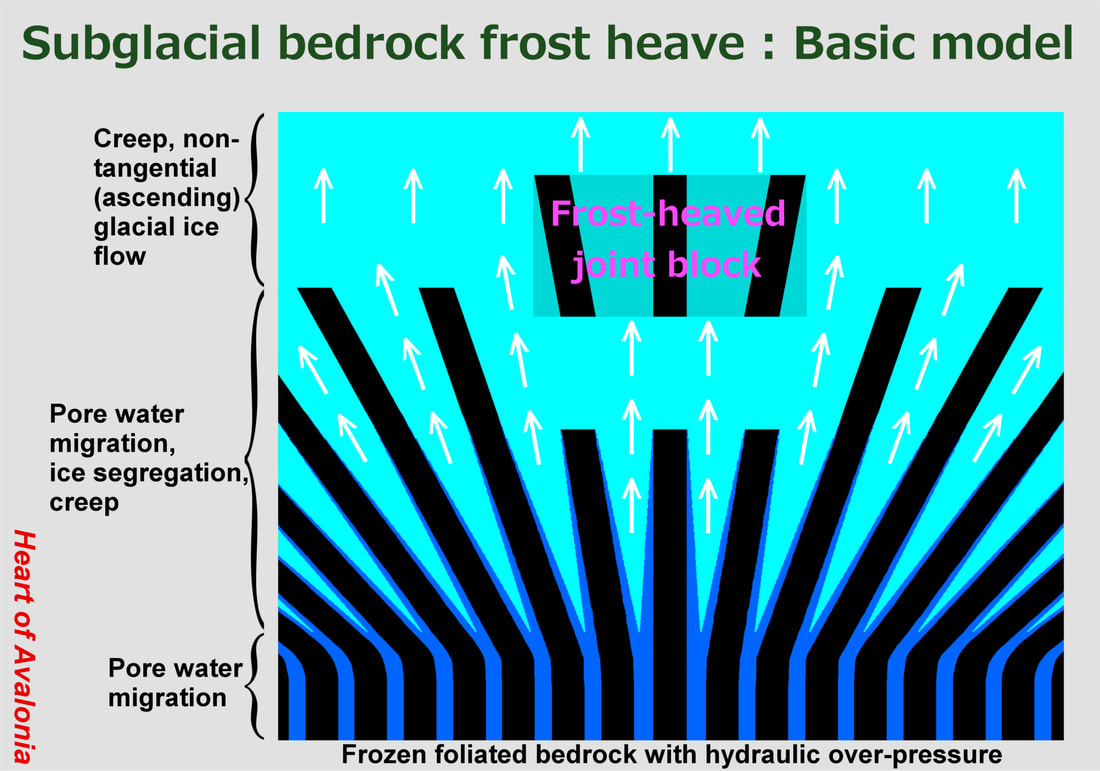
The above diagram shows the origin of a subglacial frost-heaved monolith from foliated bedrock substrate. To aid in visualization, widths and angles are not drawn in proportion. The white arrows denote ice movement by creep deformation and flow. Note that the shifted joint block moves with the ice, not through the ice. The notion of subglacial bedrock frost heave might be taken to imply that rock is pushed from behind and plows its way into obstructing glacial ice. In most cases, this kind of action is unlikely to occur. Rather, displaced rock is surrounded by co-moving ice. The subglacial frost heave process unfolds in a way that minimizes the work expended in ice deformation. This assumption forms the essence of the Basic Model for subglacial bedrock frost heave.
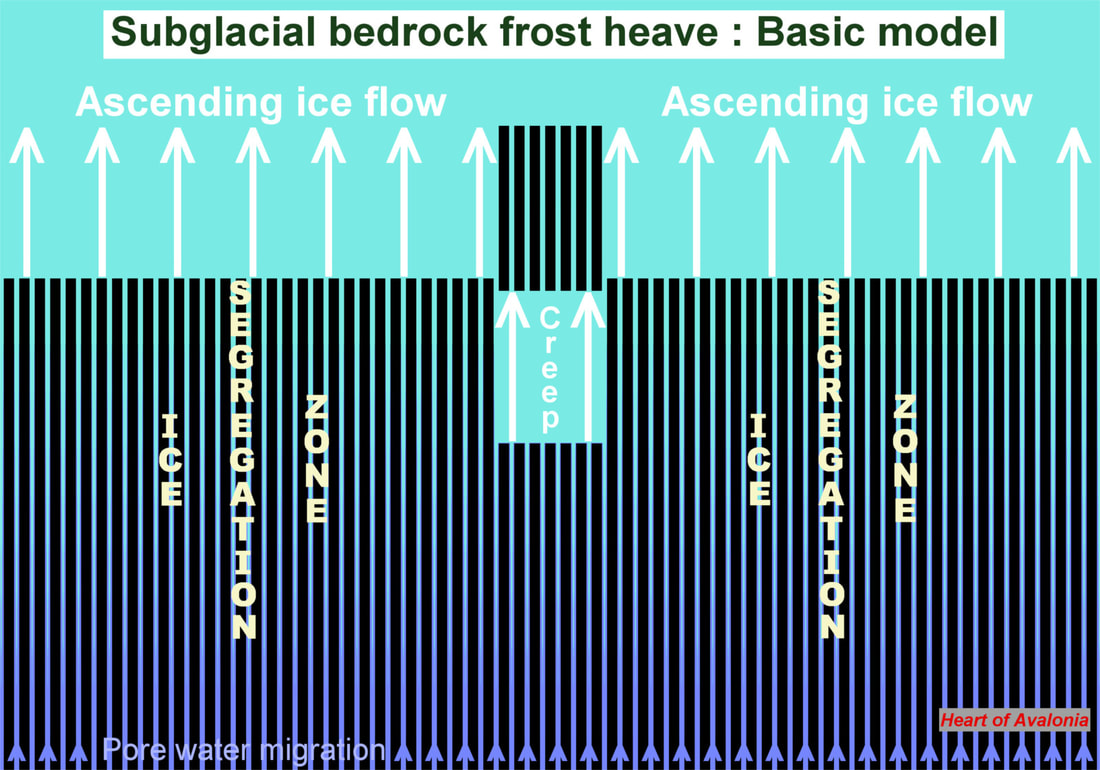
The above diagram shows a zoomed-out version of the process illustrated in the previous diagram. The base of the frost-heaved monolith can originate anywhere in the ice segregation zone, but not below it. The ice segregation zone reflects two key conditions. 1) Bedrock temperature below the pressure-adjusted melting temperature of ice. 2) Bedrock confinement insufficient to prevent tensile failure of bedrock in the stress condition created by groundwater over-pressure and/or the pressure of ice segregating in pre-existing voids. The diagram illustrates a uniform area of ascending ice flow. Variations in topography, hydrogeology, jointing and foliation of bedrock, and glacial ice pressure all combine to make nonuniform (plume) action more likely.
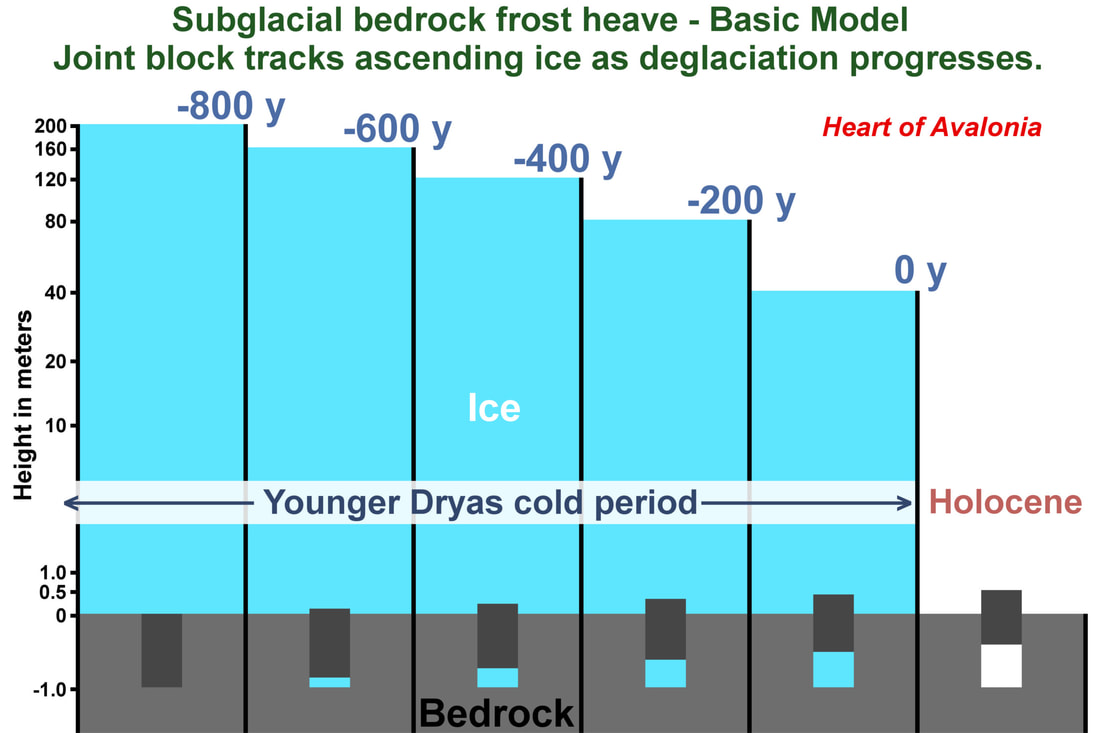
The theoretical evolution of a frost-heaved monolith over the thousand-year interval just preceding the Holocene is shown above. Note that the vertical axis of the diagram is scaled logarithmically. The monolith shifts upward by 50 cm during the thousand-year interval. The joint-block uplift is triggered and sustained by steadily declining glacial ice thickness and a corresponding buildup in the over-pressure of trapped groundwater. It is assumed that the overlying glacier, 200 m thick at the start of the diagram, had been cooled to a subfreezing basal temperature during the preceding 200 years (interval not shown in diagram) of polar climate conditions associated with the onset of the Younger Dryas cold period.
The question of whether volumes of "rebound" groundwater released from bedrock during glacial unloading are sufficient to cause significant frost heave remains open. Water has a bulk modulus of approximately 2 GPa. If hydrostatic pressure at the bedrock surface were reduced by 2 MPa, then an unobstructed vertical column of subglacial groundwater would rebound upward by 0.1 % relative to adjacent rock. This rough calculation implies that, per unit cross-sectional area of water, an aquifer extending 500 m deep could rebound sufficiently to drive 50 cm of bedrock frost heave. The calculation overstates expected frost heave by a large factor. Calculated per unit of bedrock cross-sectional area, the rebound-driven frost heave would be multiplied by the porosity of the bedrock, for example, by 1%.
In addition to the elastic rebound of compressed water, there is also the possibility that deglaciation would generate an elastic recovery in heterogeneous bedrock that would tend to expel groundwater (see Technical Note 4: Glacial Loading - Faults and Voids). Furthermore, groundwater might have been pressurized to 5 MPa or more during glacial maximum conditions and then remained pressurized over an extended period (reaching into the Younger Dryas interval) because of low bedrock permeability and correspondingly low groundwater migration rates. Probably the most significant factor affecting rebound water volumes is the tendency of groundwater movement to concentrate along certain preferred paths. A relatively large volume of pressurized groundwater could cause extensive local frost heave when released to the surface in a limited area.
The question of whether volumes of "rebound" groundwater released from bedrock during glacial unloading are sufficient to cause significant frost heave remains open. Water has a bulk modulus of approximately 2 GPa. If hydrostatic pressure at the bedrock surface were reduced by 2 MPa, then an unobstructed vertical column of subglacial groundwater would rebound upward by 0.1 % relative to adjacent rock. This rough calculation implies that, per unit cross-sectional area of water, an aquifer extending 500 m deep could rebound sufficiently to drive 50 cm of bedrock frost heave. The calculation overstates expected frost heave by a large factor. Calculated per unit of bedrock cross-sectional area, the rebound-driven frost heave would be multiplied by the porosity of the bedrock, for example, by 1%.
In addition to the elastic rebound of compressed water, there is also the possibility that deglaciation would generate an elastic recovery in heterogeneous bedrock that would tend to expel groundwater (see Technical Note 4: Glacial Loading - Faults and Voids). Furthermore, groundwater might have been pressurized to 5 MPa or more during glacial maximum conditions and then remained pressurized over an extended period (reaching into the Younger Dryas interval) because of low bedrock permeability and correspondingly low groundwater migration rates. Probably the most significant factor affecting rebound water volumes is the tendency of groundwater movement to concentrate along certain preferred paths. A relatively large volume of pressurized groundwater could cause extensive local frost heave when released to the surface in a limited area.
Two Examples


|


|
The above photos show different views of a tall, slender frost-heaved feature (cluster of monoliths) occurring in foliated sedimentary rock. The same feature is also shown in the photo at the beginning of this section. The tape seen in the fourth (bottom, right) photo reads 110 cm at the point where it bends. This frost-heave occurrence exemplifies the delicate and unstable balance between forces acting on bedrock fragments during subglacial frost heave. The cluster of monoliths comprising the tall center group is flanked by frost-heaved bedrock that has been shifted upward by a substantially lesser amount. Both the narrow gap between the tall monoliths and the wider gap where the hammer stands vertically (second, top-right photo) appear to reflect sections of bedrock that are unshifted by frost heave. Within the context of the Basic Model, ice moving upward from foliated bedrock caused joint widening and allowed nearby blocks to undergo differential shifts. The relative ice-rock displacements were accommodated by ice creep in the narrow gaps between blocks, with the creep deformation taking place over hundreds of years. After gaining substantial displacement, the taller blocks were primarily being pulled upward by adjacent rising ice rather than being pushed upward by ice from below.

The tall free-standing monolith seen on the skyline of the above photo might, at first glance, suggest an origin in a subaerial frost-heave environment. However, convincing evidence from nearby frost-heave features points to a subglacial origin for the pictured feature along with many other large bedrock frost-heave occurrences found in an extended surrounding area. Ice-induced joint widening is prominent in the strongly foliated and heavily cross-jointed sedimentary bedrock.


|


|
Views of the frost-heaved monolith taken from different angles are shown above. The rock surrounding the monolith is disrupted by frost heave and, within the context of the Basic Model, reflects ice rising from joints widened by subglacial ice segregation. The tape seen in the fourth (bottom, right) photo reads 200 cm at the point where it bends. The bottom end of the tape touches debris at the bottom of a fissure adjacent to the monolith. The tape reaches 93 cm below ground level and the monolith extends 107 cm above ground level. Given that ice was ascending on all sides of the tall block, it is not unexpected to see the large differences in heights between the tall block and the adjacent blocks. Once a block shifts upward, the resistance to its further upward motion diminishes. Shear loading by ascending ice acting on the above-ground sides of the block counteracts shear loading (drag) associated with ice deformation in the narrow gaps surrounding the below-ground portion of the block. The positive dependence of the net force acting to shift a block on the amount of shift already realized makes the subglacial frost-heave process inherently unstable.